I segnali elettrici a 24V cc sono da decenni lo standard per i circuiti di controllo industriali comprendenti PLC, sensori, contatti ed attuatori. Lo specifico valore di 24Vdc è emerso come standard de facto a partire dagli anni 50, a scapito di altri livelli di tensione come 115Vac e 24Vac, per una somma di diverse motivazioni tecniche che andiamo ad elencare, ed anche per l’uso di tale tensione su apparecchiature e mezzi aero-navali militari.
Motivazioni Tecniche
Immunità ai disturbi: i segnali a 24 V dc sono relativamente immuni ai disturbi elettrici e alle interferenze che si verificano comunemente negli ambienti industriali dove sono presenti motori elettrici e commutazione di carichi elettrici che generano interferenze elettriche . Ciò rende i segnali più stabili e affidabili, ad esempio rispetto ai segnali 5V, migliorando l’affidabilità del sistema di controllo.
Sicurezza: 24 VDC è un livello di tensione sicuro. Fornisce una tensione sufficiente per alimentare sensori, attuatori e altri dispositivi senza comportare rischi elettrici per l’uomo. Tensioni più elevate potrebbero essere pericolose in caso di contatto accidentale.
Economicità: I componenti (BJT all’inizio) necessari per ingressi ed uscite digitali a 24V dc erano più convenienti rispetto a quelli necessari per altri livelli di tensione.
Bassa “impronta” energetica: Il funzionamento a 24V c.c. permette di eccitare un relè di potenza con bobina a 24V con pochi mA. Ciò permette di usare cavi di segnale di diametro ridotto e di poter piazzare il relè a distanza dal controllore, Risparmiando così sul costo del cavo ed avendo poche perdite di tensione e potenza sui circuiti di comando.
In sintesi l’uso della tensione 24V CC per i circuiti di controllo industriali offriva ed offre il miglior compromesso tra sicurezza elettrica, immunità ai disturbi, costo, compatibilità ed è diventata lo standard de facto per i circuiti di controllo industriali comprendenti PLC, sensori, contatti ed attuatori.
Da standard di fatto (market-driven standard) a norma
Per avere dei riferimenti più stabili e precisi la maggiore organizzazione mondiale nel campo elettrotecnico/elettronico ha normato molti ambiti delle applicazioni PLC e controllori industriali con la norma IEC 61131 del 1993. In particolare la seconda parte di questa norma, la IEC 61131-2, specifica requisiti fisici sugli ingressi ed uscite dei controllori programmabili; vengono definiti i livelli e le soglie per gli ingressi e le uscite digitali, si veda ad esempio le uscite del controllore OEM BB536.
One of the most important things we should take into account when we decide to develop a new embedded system are all possible functioning conditions where our device will be used by customers. For an user of a desktop PC is quite normal asking to execute a shutdown procedure before powering off his/her system, but for an user of an embedded system this is not true at all! In fact embedded system such as ADSL modems, wifi access points or repeaters, printers (even if some printers require to execute proper shutdown) ecc. are simply disconnected from power supply by their users without any shutdown procedure.
However these devices are all GNU/Linux based as far as our Desktop PC (I know, Windows rules on PCs! But this is true at least for my PC) so how we can assure that the file system of our embedded device and its applications will continue functioning at next boot? What can prevent a system failure in case of power failure?
Well to do so we have to consider several techniques to help the embedded system we’re currently developing in tolerate a catastrophic event as a power failure. We can use four major different solution levels.
Hardware solutions
Hardware solutions are quite expensive respect to a fully software solution but is some circumstances we cannot do without them at all! We must consider them in case our application is so important that it must continue running even in case of power failure.
A first solution is to use a battery (or a super capacitor). With a battery our system will work even without main power supply but, in order to have everything under control, we should have a special signal that informs the CPU about the power failure so the system will have the time to do a safe and controlled power off. The advantage of this solution is that we can implement it even if our system haven’t a dedicated low power modes of functioning (as reducing its main CPU clock for instance which is required in case the system should continue functioning on battery power) but it simply needs to manage an interrupt line which can be used to signal an userland process to start the shutdwon procedure when power gets low. A drawback of this approach is that batteries will require periodic testing and replacement with age in order to assure enough time to do the shutdown procedure safely.
Another important thing to do is knowing the characteristics of the storage devices we’re going to use on the system. For instance if we decide to use hard disks we should consider that some of them ignore cache flush commands from the OS, while we had cases where some models of SD cards or USB mass storage devices would corrupt themselves during a power failure, but industrial models (such as eMMC) did not have this problem (unluckily this information was not always published in the datasheet, and had to be gathered by experimental testing). That’s why some developers decide to not use devices as SD or eMMC (or similar) but to use directly flash chips instead. This because, even if all these devices are (NAND) flash based, SD cards and eMMC chips have a dedicated and not open source controller while if we use bare NAND flash chips we can put over them a well know and open source controller. The final result is the same, a Linux block device where we can mount a file system but the way we get it is completely different!
From the developer point of view both devices are seen as block devices bused on NAND flash but the former is closed source while the latter is open source!
Bootloader solutions
To help us in system recovering can came in action the bootloader too. It usually is a piece of software complex enough to understand when the system is not able to do a correct boot procedure. In this case we can use the bootloader to do some automatic or manual activated steps that can restore a working settings.
As first thing to do is setting up our bootloader in such a way it can detect presence of a USB mass storage disk or a microSD and, if so, to boot from those devices. In this manner we can easily start an alternate system which in turn can reset our system to a well defined factory configuration (note that this procedure can also be executed by pressing a key or other techniques).
Another thing we can do is to program a watchdog system that can reset our board if not continuously refreshed due a failure condition (e.g. an unmountable root file system or a main application crash), then the bootloader, during the new reboot, can detect this condition and then starting a recovery procedure as above to resolve the problem.
Kernel solutions
When we must keep system cost low but we cannot effort expenses for a battery we still can have a good fail-save system simply by using some precautions into the kernel.
First of all we have to use a journaling file system, that is a file system that can tolerate incomplete writes due to power failure, OS crash, etc. Most modern filesystems are journaled, but we have to choose the right one. In fact we have to select the right filesystem according to the block device we have on our system. For block devices like hard disks, SD cards, eMMC chips and USB mass storage devices we can use Linux’s Ext4 file system, while for NAND flash chips we should use something like JFFS2 or (better) UBIFS.
In any case, unless our application needs the write performance, we should disable all write caching (check isk drivers for caching options) so consider mounting the filesystem in sync mode.
Another step that can increase system fault tolerance is trying to keep as far as possible application executables and operating system files on their own read-only partition(s) while read/write data should be on its own writable partition. Doing like this even if our application data gets corrupted, the system should still be able to boot (albeit with a fail safe default configuration).
However in some circumstances keeping the root file system read-only is not easy (for instance whhen we decide to use a standard distribution) that’s way we can decide to use some tricks to keep the root file system writable but protecting anyway our important files:
We can opening individual files as read-only (e.g. by using something like fp = fopen("configuration.ini", "r")).
We can use file mode bits and then setting important files as read-only (e.g. with chmod command used as chmod a=r configuration.ini).
We can initially mount a partition as read-only and then remounting it as read-write when we need to write data (e.g. by using mount -o remount,rw /).
We can use file system overlay to mount as read-only whole filesystem and then turning it read/write again but putting on it a transparent layer where we can put our modifications.
This last solution is very tricky since allow us to have a read-only file system with on top a read/write transparent layer which in turn allows us to see every file on lower read-only layer as it was read/writeable!
In the above figure we have a physical disk splitted into two partition: the first one holds all files needed to our system to work while the second one can be completely void. Once we mount partition 2 in read/write mode over partition 1 as read-only as overlay what we get is a logical disk mounted in read/write mode where when we write a file we put it into partition 2 while when we read it we get its contents from partition 2 if it exists there, otherwise we go in deep e we get the contents from partition 1.
The advantage of this solution is that we can wipe out all modification and return to factory settings at once just deleting partition 2!
Another solution can use, as second partition of the above example, a RAM disk so that temporary files are store into RAM. If we keep those writes off-disk we eliminate them as a potential source of corruption and we also reduce flash wear and tear. The disadvantage is that each time we reboot the system all modifications (if not saved elsewhere) will vanish.
Application solution
Even if we’re going to use whatever we saw before we still take into account that also our custom application should avoid bad operations may vanish any hardware or kernel effort.
Let’s suppose we are using a journaling filesystem on a system which has no batteries, in this situation we should think that we’re safe since, even without the battery support, our file system is safe. Well, this is certainly sure but having a journaling file system do NOT mean that we cannot loose our data! In fact if we have an important file (for example a configuration file or a database file) we periodically update and, during one of these updates, the power fails we can be sure that the file system will not be corrupted but our file will be truncated for sure!
To avoid this possibility the first thick we can do is considering to do write operations in a well defined order in such way that our data will not be lost. An example of bad code is the following:
fp = fopen("configuration.ini", "w+")); ret = fread(buf, rsize, 1, fp);
fpw = fopen("configuration.ini.new", "w")); ret = fwrite(buf, wsize, 1, fpw); if (ret != wsize) {
} else { fclose(fpw); ret = fmove("configuration.ini", "configuration.ini.old"); if (ret > 0) ret = fmove("configuration.ini.new", "configuration.ini"); }
In this manner we are sure that in any case we have a copy of our data (that is the new modified version or the the old not-yet modified one) we can recover in case of power failure.
In order to be able to recover as gracefully as possible our system we should also maintain at least two copies of its configuration settings, a primary and a backup. If the primary fails for some reason, switch to the backup. Also we should consider mechanisms for making backups whenever whenever the configuration is changed or after a configuration has been declared good by the user. Do you have a Boot Loader or other method to restore the OS and application after a failure? 7e. Make sure your system will beep, flash an LED, or something to indicate to the user what happened.
Conclusions
There are several things we can do to resolve or (better) to avoid a system failure due a power loss and they can be used in different manners so the best thing to do is using our experience to know when enhancing the hardware is mandatory or when we can solve all our problems by using a software solution only.
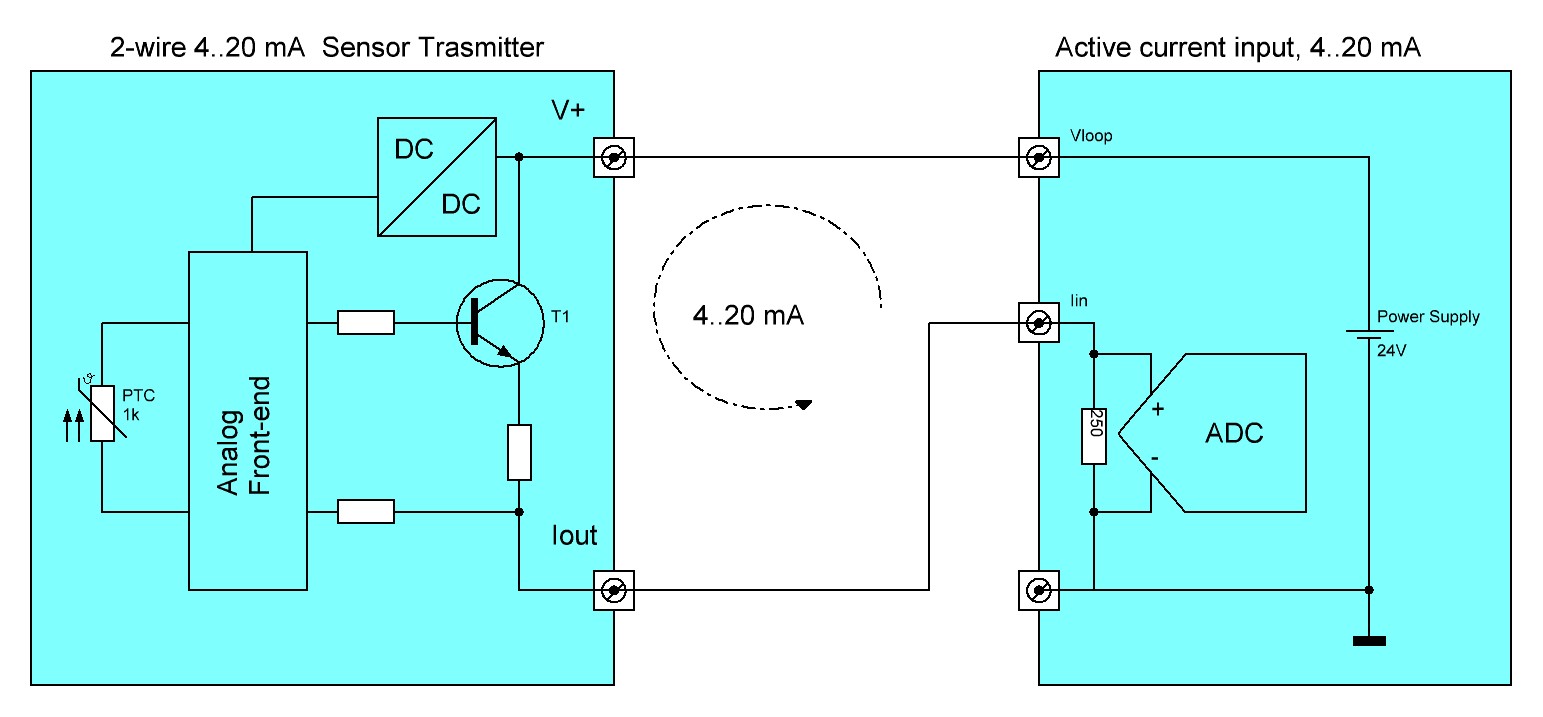
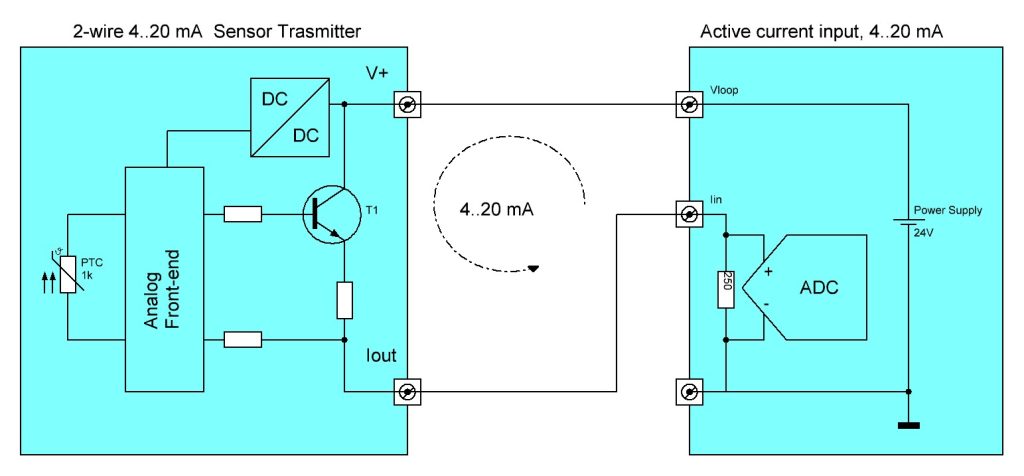
La trasmissione dei segnali analogici per il controllo di processo ha uno standard de-facto nel 4..20mA Current Loop. Questo tipo di segnale risale agli anni 50 ed è ancora molto usato nonostante la moltitudine di fieldbus digitali alternativi per i suoi vantaggi intrinseci ed il basso costo:
1) La lunghezza del cablaggio non conta
L’opportunità di avere un segnale trasmesso in corrente invece che in tensione in tutti i casi in cui non sia nota a priori la lunghezza del cablaggio è nota. La corrente in una maglia unica è la stessa in tutti i punti del circuito qualunque sia la lunghezza del cablaggio, ciò non è più vero per le tensioni.Ogni conduttore reale presenta una resistenza per unità di lunghezza. Più lungo è il cavo, maggiore è la resistenza. Corrente*Resistenza=caduta di tensione (perdita) sul cablaggio.Così, se una sorgente di segnale può essere 10V o 20mA ad esempio, le perdite sul cablaggio comporteranno una tensione inferiore misurata all’ingresso del ricevitore mentre la corrente rimarrà invariata al 100%, quindi 20mA.Una configurazione molto comune è quella di avere la sorgente di controllo della corrente (0-100% segnale diventa 4-20mA), che si chiude su una resistenza da 250ohm al ricevitore, il risultato interno all’elettronica del ricevitore è un comodo ed affidabile segnale da 1-5V su cui operare.
2) Con un cablaggio a due fili posso trasmettere sia l’alimentazione che i dati del sensore.
3) Una linea di segnale analogica in corrente è maggiormente immune di un segnale in tensione.
Un sensore ha anche una bassa potenza, il suo segnale analogico 0..10V di uscita “port” poca corrente, quindi richiede una resistenza di ingresso del ricevitore piuttosto elevata (ordine anche dei Mega Ohm). Rumori e disturbi EMI inducono correnti non volute. Se queste correnti indotte, per quanto basse, finiscono su una resistenza elevata il disturbo risultante sarà molto più elevato dell’effetto in un circuito con segnale in corrente dove le tensioni sono tipicamente delle centinaia di Ohm.
4) Il segnale fuori norma può essere interpretato come allarme.
Se il ricevitore rileva 0mA significa che il cablaggio con il sensore è interrotto.È anche possibile programmare il sensore in modo da regolare la corrente d’anello su livelli fuori intervallo in caso di guasto. Ad esempio 3,5 e 23 mA. In questo modo, il current loop può notificare al sistema l’errore del sensore.
Ci sono diverse possibili configurazioni circuitali per il current loop, quella che riunisce tutti i vantaggi descritti e che è la più usata è illustrata nella figura seguente:
Il blocco a destra nelle figura è tradizionalmente incluso nel modulo di ingresso analogico di un PLC. Con i moderni sistemi di automazione lo stesso blocco può essere accessibile da remoto via Internet. Si veda ad esempio il Web-IO Analogico 57761.
Costruisci, installa e sviluppa i tuoi circuiti tramite tutorial passo-passo ed utilizza questa guida piena di esempi pratici per accedere a diversi tipi di periferiche per monitorare e controllare il tuo ambiente domestico. Il libro è stato scritto dal nostro Co-Chief e Senior Software Engineer Rodolfo Giometti – Feb 2016 – 378 pagine
Caratteristiche principali
Costruire, installare e sviluppare circuiti tramite tutorial passo-passo ed esempi pratici, dalla configurazione iniziale alla gestione driver di periferica
Accedi a diversi tipi di periferiche per computer per monitorare e controllare il proprio ambiente domestico utilizzando questa guida
Questo libro si sviluppa attraverso 10 capitoli tutti concentrati su di un unico progetto pratico di automazione domestica
Descrizione libro
La BeagleBone è un mini PC dove gira Linux. Può connettersi a Internet e può eseguire diversi sistemi operativi come Android e Ubuntu. La BeagleBone viene utilizzata per una varietà di scopi diversi, da progetti semplici come la costruzione di un termostato a quelli più avanzati come sistemi di sicurezza della casa. Ricco di esempi reali, questo libro vi fornirà esempi di come collegare diversi sensori e ed attuatori alla BeagleBone Black. Imparerete come accedere ad essi al fine di realizzare sistemi di monitoraggio e controllo dai più semplici a quelli più complessi che vi permetteranno di prendere il controllo della casa. Troverete anche esempi software per implementare interfacce web utilizzando PHP/HTML e JavaScript, e come utilizzare le API per interagire con un account Google Docs, WhatsApp o Facebook. Questa guida è un tutorial prezioso se si prevede di utilizzare un BeagleBone Black in un progetto di automazione domestica.
Cosa si può imparare
Costruire un rilevatore di CO (e di altri gas) con un allarme acustico e LED per segnalare alte concentrazioni
Registrare dati ambientali e tracciarli graficamente
Sviluppare una semplice interfaccia web con una piattaforma LAMP
Preparare interfacce web complesse in JavaScript e come fare un flusso di dati video da una webcam
Utilizzare delle API per ottenere l’accesso a un account Google Docs o un account WhatsApp/Facebook per gestire un sistema di automazione domestica
Aggiungere un driver personalizzato per gestire un LED con diverse frequenze di lampeggiamento
Scoprire come lavorare con vari componenti elettronici per costruire piccoli circuiti
Utilizzare un NFS, sensori di temperatura, relè e altre periferiche per monitorare e controllare l’ambiente circostante
Now we can enlarge time’s characters by using figlet utility. This tool reads from stdin (or on the command line) a string and reproduces it on stdout using ASCII-art as below:
Serial ports are really important in Industry Automation, in fact they are widely used to communicate between computers and their peripherals (or between computers too). Usually these serial peripherals use standard baud rates but sometimes they not! So how we can force our serial controller to use these non standard speeds?
Looking around into the driver
The Linux kernel is an open-source project so to better answering to the above question we can start by directly looking into the source, in fact if we take a look into file linux/drivers/tty/tty_ioctl.c we can see the following code for the set_termios() function:
Here we can see that input and output speed is read from the termios variables by using specific functions. Then if we take a look at one of these functions, for example tty_termios_input_baud_rate() , we see the following code:
speed_t tty_termios_input_baud_rate(struct ktermios *termios) { #ifdef IBSHIFT unsigned int cbaud = (termios->c_cflag >> IBSHIFT) & CBAUD; if (cbaud == B0) return tty_termios_baud_rate(termios); if (cbaud == BOTHER) return termios->c_ispeed;
Here we notice that the BOTHER define can be used to specify a generic value for baud rate instead of the classic fixed speed defines like B115200 & friends. In this scenario we can go further searching where BOTHER is defined and we can discover that everything is into file linux/include/uapi/asm-generic/termbits.h , below is what we can found:
So we discovered that struct termios2 can be used to specify serial communication parameters from the userland with non standard speeds. Let’s see how.
A practical example
Below is a simple code in C that we can use to set custom baud rate. It’s quite obvious that this code can work if and only if the underlying driver is supporting these advanced settings.
By using the ioctl() command TCGETS2 we retrieve from the kernel the current serial port configuration where we remove the (old and) current baud rate and then we enable custom baud rate with BOTHER .
As final note, don’t forget that the above code is just an example so we should add return values checks especially for systems calls!
Vi è mai capitato di dover creare un file binario contente dei valori esadecimali? Ad esempio se dovreste creare un file binario contenente i valori esadecimali della stringa BEBABEBAEFBEADDEBEBABEBAEFBEADDE, come fareste?
Lo so, e un’operazione poco frequente perché, di solito, serve il contrario e cioè poter leggere il contenuto di un file binario; cosa che si può fare ad esempio con il comando od.
Ma per fare l’operazione inversa, cioè creare un file binario contenente dei valori ben definiti, come si fa?
Semplice, si usa il comando xxd come segue:
$ echo "0: BEBABEBAEFBEADDEBEBABEBAEFBEADDE" | xxd -r > /tmp/file.bin $ od -tx1 < /tmp/file.bin 0000000 be ba be ba ef be ad de be ba be ba ef be ad de 0000020
In pratica questo comando, attraverso una speciale sintassi, permette di fare l’operazione inversa di od.
Most GNU/Linux distributions offer the possibility to install OpenOCD directly using their packages management system, however these package may refer to not so updated releases of the software and this means that some CPUs may not be supported at all! That’s way could be very useful to know how to install OpenOCD from sources in order to get its latest release!
Downloading the code
First of all we need to download the official GIT source or a related mirror (I’m going to use the Spen’s Official OpenOCD Mirror):
git clone https://github.com/ntfreak/openocd.git
The needed extra packages
Once the sources have been downloaded we need some extra packages in order to get them compiled. On my Ubuntu Xenial I used the following command to install such software:
Now we are ready! Just enter into the openocd directory and executing the bootstrap script as follow:
$ cd openocd $ ./bootstrap
After that we can start configuring the sources by using the usual configure script which is able to auto detect our hardware. However we can force any special feature we want by simply adding one or more option arguments as shown below:
$ ./configure --enable-cmsis-dap
In the command above I force the CMSIS-DAP compliant debugger support which I need to program my SAME70 based board.
When configure script has finished its job we can start the OpenOCD compilation and installation with the usual UNIX commands:
$ make -j8 $ sudo make install
Please, note that I used the -j8 option argument in order to have 8 compilation threads and the sudo command to be able to install the software into the system without permissions erros.
Testing the code
Once the compilation is finished we can test our new OpenOCD as follow (remeber that for this test I used my SAME70 based board). On a terminal we have to execute OpenOCD specifying the board’s script we wish to manage:
Note that the sudo command may be mandatory in case you need to use an USB connection!
Note also that the path /usr/local/share/openocd/scripts/board/atmel_same70_xplained.cfg may vary in case you decide to install OpenOCD into a custom directory.
If everything works well you should see something like the following:
$ sudo openocd -f /usr/local/share/openocd/scripts/board/atmel_same70_xplained.cfg Open On-Chip Debugger 0.10.0+dev-00512-gfd04460 (2018-08-09-18:25) Licensed under GNU GPL v2 For bug reports, read http://openocd.org/doc/doxygen/bugs.html Info : auto-selecting first available session transport "swd". To override use 'transport select <transport>'. adapter speed: 1800 kHz cortex_m reset_config sysresetreq Info : flash bank command srst_only separate srst_gates_jtag srst_open_drain connect_deassert_srst Info : Listening on port 6666 for tcl connections Info : Listening on port 4444 for telnet connections Info : CMSIS-DAP: SWD Supported Info : CMSIS-DAP: FW Version = 02.09.0169 Info : CMSIS-DAP: Serial# = ATML2637010000000000 Info : CMSIS-DAP: Interface Initialised (SWD) Info : SWCLK/TCK = 1 SWDIO/TMS = 1 TDI = 1 TDO = 1 nTRST = 0 nRESET = 1 Info : CMSIS-DAP: Interface ready Info : clock speed 1800 kHz Info : SWD DPIDR 0x0bd11477 Warn : Silicon bug: single stepping will enter pending exception handler! Info : atsame70q21.cpu: hardware has 8 breakpoints, 4 watchpoints Info : Listening on port 3333 for gdb connections
Now we can use different connections types to control OpenOCD. I use the telnet connection as below:
$ telnet localhost 4444 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. Open On-Chip Debugger >
Then I can easily reprogram the CPU’s internal flash with the following commands:
> halt > flash write_image erase unlock /tmp/nuttx.hex 0 ihex auto erase enabled auto unlock enabled device id = 0xa1020e00 erasing lock regions 0-8... erasing lock region 0 erasing lock region 1 erasing lock region 2 erasing lock region 3 erasing lock region 4 erasing lock region 5 erasing lock region 6 erasing lock region 7 erasing lock region 8 wrote 147456 bytes from file /tmp/nuttx.hex in 3.278660s (43.920 KiB/s) > reset >
Note that file /tmp/nuttx.hex is the new image I wish to program into my CPU.